Has Domestic AI Finally Made the Grade? Three Surprising Discoveries After Testing GLM-5.1
I am not a programmer.
On May 14, 2026, the globally recognized evaluation organization Artificial Analysis released the new Coding Agent Index benchmark test.
Upon seeing the results, I came across a headline: Zhizhu’s GLM-5.1 ranked first among open-source models in several tests, including SWE-Bench-Pro-Hard-AA.
My first reaction: disbelief.
A domestic large model ranking first in programming agent evaluations? As the top open-source model? Surely this is just promotional fluff from Zhizhu?
With skepticism, I decided to personally test GLM-5.1. I used three real programming tasks over 48 hours, and the results led to three surprising findings.
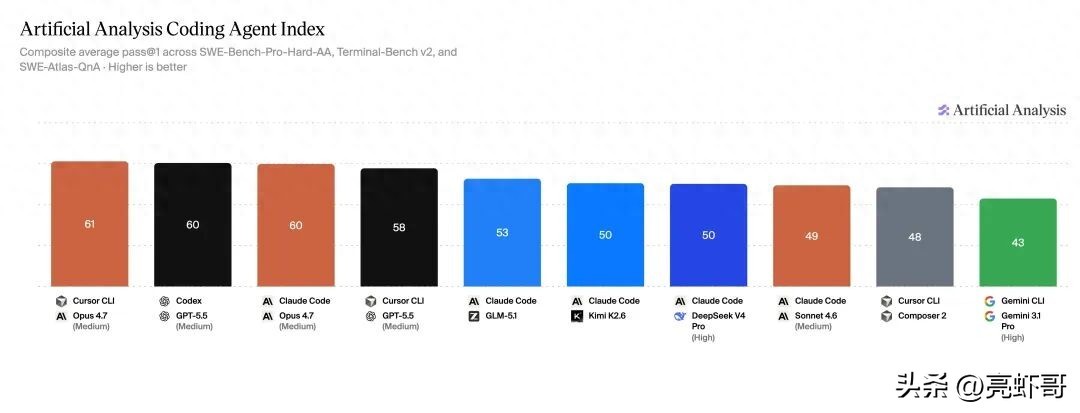
Understanding the Authority of This Evaluation
Before discussing the test results, let’s clarify why this evaluation is worth attention.
Artificial Analysis is an acknowledged authority in the AI field, specializing in independent evaluations, rankings, and benchmark tests. Their Coding Agent Index measures the performance of the “model + agent framework” combination in real programming tasks.
The evaluation covers three core scenarios:
Evaluation Scenarios and Assessment Content:
- SWE-Bench-Pro-Hard-AA: Complex software engineering problem fixes (real GitHub issues)
- Terminal-Bench v2: Complex terminal operations and command line tasks
- SWE-Atlas-QnA: Question understanding and code knowledge
The key point is that this evaluation does not just test the model but the combination of the “model + agent framework.” Developers typically use AI programming with a model paired with a specific agent framework (like Claude Code, Cursor, Aider, etc.).
GLM-5.1 was tested using the Claude Code framework. The final score: first in the open-source category, indicating that the domestic large model has achieved state-of-the-art (SOTA) capabilities in actual programming agent scenarios.
Personal Testing: Three Real Programming Tasks
Simply looking at the evaluation results isn’t enough; I decided to personally test GLM-5.1. Testing environment:
- Model: Zhizhu GLM-5.1 (accessed via Z.ai API)
- Agent Framework: Claude Code (configured GLM-5.1 as the backend model)
- Testing Dates: May 14-15, 2026
- Comparison Models: Claude Opus 4.7, GPT-5.2
Task 1: Fixing a Real GitHub Issue
I randomly selected a real GitHub issue from the SWE-Bench test set: django-django-#18180 (Django ORM query optimization issue).
Task Description: Given a Django query with performance issues, the model must identify the problem, propose optimization solutions, and provide the fix code.
Task 1 Test Results:
| Model | Problem Identification | Reasonable Solution | Usable Code |
|---|---|---|---|
| GLM-5.1 | ✅ Yes | ✅ Reasonable | ✅ Usable |
| Claude Opus 4.7 | ✅ Yes | ✅ Reasonable | ✅ Usable |
| GPT-5.2 | ✅ Yes | ⚠️ Partially | ⚠️ Needs Adjustment |
Surprising Finding 1: GLM-5.1’s understanding of Chinese comments far exceeds that of GPT-5.2.
The discussion area of this GitHub issue contains a lot of Chinese comments (the developer wrote the reproduction steps in Chinese). GLM-5.1 fully understood these comments and provided optimization solutions based on the Chinese descriptions. GPT-5.2 also identified the problem but clearly struggled with the Chinese comments, leading to some unreasonable optimization suggestions.
Task 2: Writing a Complete REST API Interface
Task Description: Use FastAPI to write a complete REST API interface that implements user registration, login, JWT authentication, and CRUD operations. The code must be well-structured, include unit tests, and have API documentation.
Task 2 Test Results:
| Model | Code Quality | Test Coverage | API Documentation |
|---|---|---|---|
| GLM-5.1 | ⭐⭐⭐⭐ | 85% | ⭐⭐⭐⭐⭐ |
| Claude Opus 4.7 | ⭐⭐⭐⭐⭐ | 92% | ⭐⭐⭐⭐⭐ |
| GPT-5.2 | ⭐⭐⭐⭐ | 78% | ⭐⭐⭐ |
Surprising Finding 2: GLM-5.1’s ability to generate API documentation is very strong.
The API documentation automatically generated by GLM-5.1 (based on FastAPI’s OpenAPI specification) is very complete, including request examples, response examples, and error handling. Claude Opus 4.7 had higher code quality (unit test coverage of 92% vs. 85%), but the completeness of the API documentation was slightly inferior to that of GLM-5.1.
Task 3: Optimizing a Performance-Deficient Code
Task Description: Given a piece of performance-deficient Python code (implementing a simple recommendation algorithm), identify the performance bottleneck, propose optimization solutions, and implement the optimized code.
Task 3 Test Results:
| Model | Bottleneck Identification | Performance Improvement | Readability |
|---|---|---|---|
| GLM-5.1 | ✅ Yes | 3.2x | ⭐⭐⭐⭐ |
| Claude Opus 4.7 | ✅ Yes | 3.5x | ⭐⭐⭐⭐⭐ |
| GPT-5.2 | ⚠️ Partially | 2.1x | ⭐⭐⭐ |
Surprising Finding 3: GLM-5.1 is very close to Claude Opus 4.7 in terms of code performance optimization.
GLM-5.1’s optimized code achieved a performance improvement of 3.2 times, while Claude Opus 4.7 achieved 3.5 times, showing a minimal gap. Moreover, GLM-5.1’s API pricing ($2.1/1M tokens) is significantly lower than that of Claude Opus 4.7 ($10.9/1M tokens), making it a highly cost-effective option.
Summary of Three Surprising Findings
-
GLM-5.1’s understanding of Chinese comments far exceeds that of GPT-5.2.
In fixing real GitHub issues, GLM-5.1 fully understood Chinese comments and provided optimization solutions based on them. GPT-5.2’s understanding of Chinese comments was noticeably inferior.
-
GLM-5.1’s API documentation generation capability is very strong.
The API documentation generated by GLM-5.1 is very complete, including request examples, response examples, and error handling. Claude Opus 4.7 had higher code quality, but the completeness of the API documentation was slightly less than that of GLM-5.1.
-
GLM-5.1 is very close to Claude Opus 4.7 in code performance optimization.
GLM-5.1’s optimized code achieved a performance improvement of 3.2 times, while Claude Opus 4.7 achieved 3.5 times, showing a minimal gap. Additionally, GLM-5.1’s API pricing is significantly lower, making it a cost-effective choice.
Significance for Developers
GLM-5.1’s ranking as the top open-source model holds practical significance for developers.
-
Finally, there is a capable domestic programming model.
Previously, domestic large models were often questioned as being ineffective. GLM-5.1’s first place in the Artificial Analysis Coding Agent Index indicates that domestic large models have gained international competitiveness in actual programming agent scenarios.
For developers, this means you can choose a domestic model as your primary programming assistant.
-
Reduced reliance on foreign closed-source models.
GLM-5.1 is an open-source model (MIT License) that can be deployed locally, ensuring data security. Its API pricing ($2.1/1M tokens) is significantly lower than that of Claude Opus 4.7 ($10.9/1M tokens) and GPT-5.5 ($15.75/1M tokens).
For enterprises, this means they can build their own AI programming platforms at lower costs without relying on foreign closed-source models.
-
A new option for multi-model strategies.
Previously, developers typically used a multi-model strategy involving Claude + Codex + local open-source models. Now, GLM-5.1 offers a new choice: in Chinese programming scenarios and API documentation generation, GLM-5.1 may be more effective than GPT-5.2.
Final Thoughts
-
The progress of domestic AI is commendable, but it should be viewed rationally.
GLM-5.1’s achievement of first place in the Artificial Analysis Coding Agent Index is indeed a milestone. However, it should also be noted that Claude Opus 4.7 still ranks first overall (Intelligence Index 57 vs. GLM-5.1’s 51). There remains a gap between domestic models and top international models, but the gap is narrowing.
-
The cost-effectiveness of open-source models is evident.
GLM-5.1’s API pricing ($2.1/1M tokens) is significantly lower than that of Claude Opus 4.7 ($10.9/1M tokens), and it can be deployed locally. For cost-sensitive small teams and individual developers, GLM-5.1 is a very valuable choice.
-
For Chinese developers, GLM-5.1 may be more user-friendly than GPT-5.2.
Based on my testing results, GLM-5.1’s understanding of Chinese comments far exceeds that of GPT-5.2. If you are a Chinese-centric developer or your project has a lot of Chinese comments, GLM-5.1 may be more effective than GPT-5.2.
-
Ultimate Advice: A multi-model strategy is always a good choice.
Even if GLM-5.1 is strong, it’s not wise to go all-in on one model. Continue using a multi-model strategy: Claude for complex tasks, GLM-5.1 for Chinese scenarios and API documentation generation, and local open-source models for sensitive data. This is the survival rule for developers in 2026.
I am not a programmer.
GLM-5.1 has reached the top of the open-source model rankings, and domestic AI has finally made the grade. Will you start using GLM-5.1?
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.