Last year, when DeepSeek V3 was released, the atmosphere in the AI community was completely different from this year.
At that time, discussions were very lively, reminiscent of the global explosion of ChatGPT, with social media flooded with tests, benchmarks, and cost analyses. Many overseas developers were discussing a Chinese large model company seriously for the first time. Both domestic and Silicon Valley companies realized that besides OpenAI, Anthropic, and Google, there were teams capable of developing models at this level.
More importantly, it was also affordable. The impact of DeepSeek was not just technical; its lower training costs, aggressive engineering optimizations, and higher inference cost-performance ratio made the entire industry rethink the competitive logic of large models, with many viewing it as a true “Open AI.”
Two weeks ago, DeepSeek V4 was released, and the industry was, of course, very attentive. Many developers ran tests and comparisons immediately, but the overall market sentiment was noticeably calmer. For ordinary users, those using Doubao or ChatGPT continued to do so, while for developers, many using Codex or Claude Code did not switch to GPT-5.5 or Claude 4.6/4.7 simply because DeepSeek V4 was cheaper.
In fact, many developers now discussing AI no longer mention model names like GPT-5.5, Claude 4.6, or DeepSeek V4. Instead, they frequently refer to Agent frameworks like Codex, Claude Code, OpenClaw, OpenCode, and Hermes.
Over the past year, the competitive focus in the AI industry has gradually shifted from the capabilities of the models themselves to the actual output value of AI. In this regard, DeepSeek V4 still lacks its own Codex.
DeepSeek V4 is Good, but Focus Has Shifted from Models
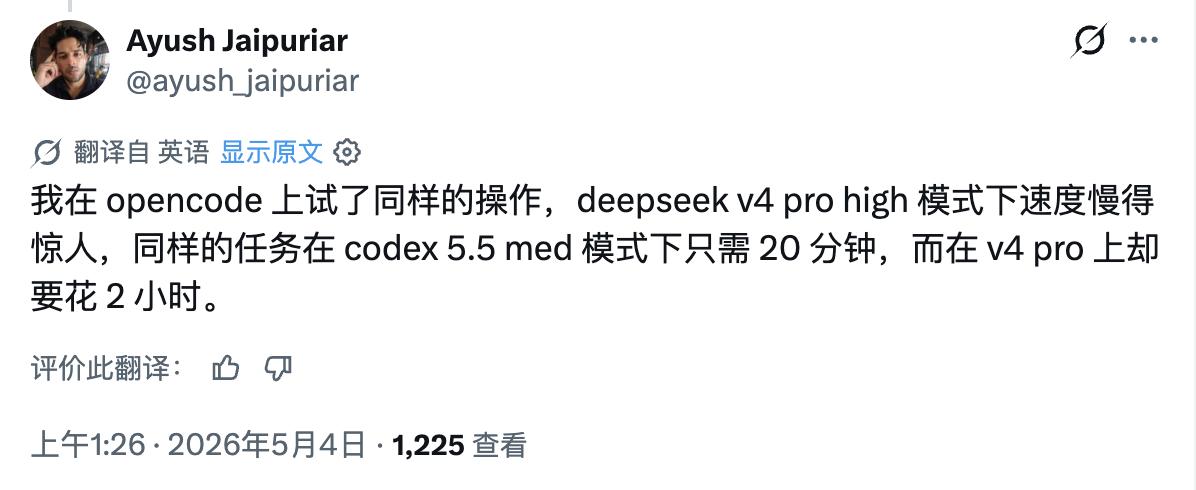
“I tried the same operation on opencode, and the speed in deepseek v4 pro high mode was astonishingly slow. The same task took only 20 minutes in codex 5.5 med mode, while it took 2 hours on v4 pro,” said X user Ayush Jaipuriar recently.
It should be noted that DeepSeek V4 is indeed a strong model. It shows significant improvements over last year’s V3 in terms of coding ability, reasoning ability, long context, and multi-turn understanding, especially in Chinese scenarios, complex logical reasoning, and long contexts. Meanwhile, amidst the price hikes of many large models both domestically and internationally, V4 is one of the few large models that has reduced its price.
However, the problem is that in the large model industry of 2026, various benchmark test results increasingly fail to reflect the actual performance of AI in real work. Last year, every time a new model was released, social media discussions immediately revolved around who surpassed whom on MMLU, who set new records on SWE-Bench, and how much improvement was made in human evaluations.
It’s not that benchmark tests are entirely without value, but developers clearly care less about them now. The reason is simple: everyone has seen too many models that perform well in tests but are not practical to use. Many benchmarks resemble exams, while real work environments are far more complex, and actual performance often outweighs price advantages.
The semiconductor and AI analysis firm SemiAnalysis recently conducted a horizontal test covering GPT-5.5, Opus 4.7, and DeepSeek V4, noting that DeepSeek V4 is currently the lowest-cost top-tier closed-source model alternative, but its capabilities have not reached a leading level.
Moreover, the method of calculating token costs is unreasonable; a more rational approach is to consider the cost of completing a task. Developer and former media person Wang Boyuan mentioned on X that he couldn’t solve a problem with a second-tier domestic model after a long time, but Codex resolved it in one go. Developer and founder of Mo Wen Xi Dong, Chi Jianqiang, also encountered issues that Claude Code couldn’t solve twice, but Codex managed to do it in one attempt.
Clearly, the actual model cost cannot simply be compared based on “official token pricing.” Not to mention the results, the actual token usage varies. Additionally, a significant upgrade in GPT-5.5 is its “efficiency,” allowing it to complete the same tasks using fewer tokens.
So even if there are some methods to use third-party models like DeepSeek V4 on Claude Code or Codex, considering factors like stability, effectiveness, and time, the vast majority still opt for the official default models, with Claude Code being Claude 4.x and Codex being GPT-5.x.
Especially in coding scenarios, the real issues developers face daily are whether AI can participate in the complete software engineering process. For instance, can it understand the entire project structure, continuously modify multiple files, call the terminal, automatically fix bugs, continue trying after errors, and maintain stable context over long periods?
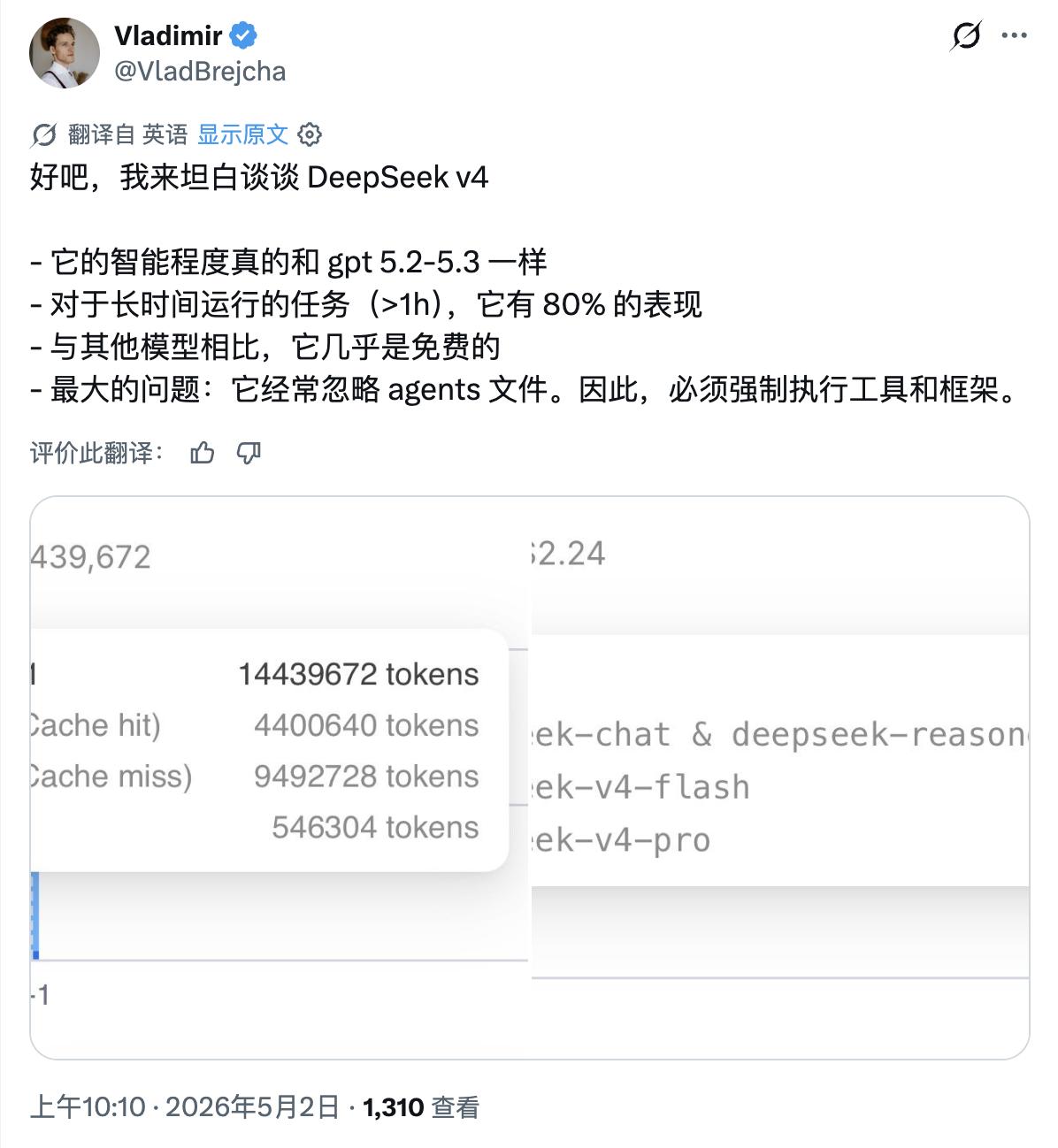
These aspects test not just “model capability” but also require a complete AI working system. Developer Vladimir, after using 14.43 million tokens of DeepSeek V4, stated that V4’s intelligence level is close to GPT-5.2/GPT-5.3, but the biggest issue is that it often overlooks agents’ files, making it necessary to enforce tools and the Harness framework in actual use.
Claude Code and Codex are truly complete products, while DeepSeek V4 is just a model. SemiAnalysis emphasized in its testing report that “a truly complete product consists of a running framework + model. Missing either one leaves you lacking.”
Over the past year, the presence of Agent frameworks like OpenClaw, Claude Code, and Codex has grown stronger. Many developers now say, “I’m using Claude Code” instead of “I’m using Claude 4.6.” Similarly, many discuss Codex rather than GPT-5.5.
DeepSeek Needs Its Own Codex
Looking back at the early days of ChatGPT’s popularity, one can see that the entire industry was focused on “dialogue” products. Whether it was OpenAI, Anthropic, or domestic manufacturers, the essence was to make models more human-like in conversation, emphasizing smarter, more natural, and more human-like models.
However, the focus of AI is now shifting from “chatting” to “working.” This change may seem like a mere shift in application, but it fundamentally alters the competitive logic of the entire industry. Previously, the most important task for model companies was to train smarter models; now, the increasingly important question is how to enable AI to truly complete tasks.
This is why terms like Agent, Workflow, Context Engineering, and Harness Engineering have emerged in large numbers over the past year. Essentially, they all address the same issue: how to integrate AI into production processes effectively.
Thus, when many developers evaluate AI coding or Agent products, while the model as a system “engine” is certainly important, the key that directly determines the actual value of AI lies in a complete system engineering approach. For instance, context management, tool invocation, long-term memory, task decomposition, error recovery, and multi-Agent collaboration. In real work, these capabilities often matter more than the advantages of the model itself.
This is why more and more people are saying that the competition in AI coding is no longer just about LLMs but about AgentOS competition.
Looking back, we can also understand to some extent the success of Claude Code and Codex. On one hand, there is the advantage of their own models in terms of capability; on the other hand, there is the vertical integration from the underlying model to the Agent framework, which can provide more stable and efficient performance in real work environments. Especially in long-task scenarios, Claude Code resembles an AI assistant capable of continuous autonomous work.
The truly significant aspect of GPT-5.5 is not just that the model is stronger, but also that the Codex workflow behind it has matured significantly. The combination of file management, tool invocation, Agent collaboration, task decomposition, and context management has qualitatively changed the capabilities and value demonstrated by AI in practice.
Recently, OpenAI officially announced that API revenue from GPT-5.5 has grown more than twice as fast as any previous version in the first week, and Codex’s revenue doubled in less than seven days. Moreover, this advantage has spilled over from AI coding to more Agent scenarios.
Friends following Anthropic and OpenAI may have noticed that both companies have been expanding Claude Code and Codex to more scenarios, including connecting to more third-party applications and platforms.
Furthermore, Claude Code has taken on the office positioning of Claude Cowork, recently launching an AI Agent tailored for banks and other financial service enterprises, while Codex emphasizes more research, documentation, and accounting tasks, not just coding.
Looking back at DeepSeek V4, although it has caught up with the industry’s forefront changes and leading camp at the model level, it still lacks its own Codex. In fact, there has been considerable demand for this, with some even open-sourcing a terminal coding agent based on DeepSeek V4 on GitHub—DeepSeek TUI, which supports Skill and many common functions on Agent frameworks.
However, this is still the work of third-party developers, and their understanding of DeepSeek V4 is unlikely to match that of the official team, making it difficult to fully leverage V4’s vertical integration advantages. The best hope is that, through feedback and demand for DeepSeek TUI, the DeepSeek team can create its own open-source Agent framework and its own Codex.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.