Introduction
GLM-5.2 has been fully opened! With a true 1M context, it can handle long tasks without forgetting important details.
Last night, Claude Fable 5 was globally taken down by a letter from the U.S. government. Just 72 hours after its launch, it was gone. Even Anthropic’s foreign employees were not allowed to use it, leaving hundreds of millions of users in shock.
In response, the domestic model has arrived: GLM-5.2, fully open, with maximum permissions for open source.
The GLM Coding Plan is now available for all users, including Lite, Pro, Max, and Team versions, effective tonight! The API will be launched next week under the MIT license, with weights freely accessible.
As one door closes, another opens.
From GLM-5 to 5.1 and now to 5.2, Zhipu has been dedicated to coding for a whole year. The 5.1 version pushed the open-source model to handle 8-hour long tasks, and with community feedback still warm, 5.2 directly increases the context to a usable 1M!
This time, GLM-5.2 has two key phrases: true 1M context, the light of domestic coding.

Community Response
In the wake of Anthropic’s actions, the announcement of the 5.2 model’s open-source status has caused a stir in the overseas community. Notable blogger AICodeKing, after testing, gave a straightforward evaluation: the model is excellent, and the code is always very clean. He managed to fine-tune a complete local model in just 30 minutes, showcasing outstanding performance across the board.
Current developer benchmarks indicate that its performance is comparable to Opus 4.8—a true domestic gem.

Zhipu had already opened a round of internal testing for coding plan users a few days ago, which is a common procedure in recent AI model releases. Feedback from our internal testing community has been overwhelmingly positive.
Some users remarked, “This is the first domestic model to reach Opus-level in my workflow.”

Another tester was more direct: “Once you use 5.2, you can’t go back to 5.1. It feels like a leap from 4.7 to 5 in large projects. It’s exhilarating.”
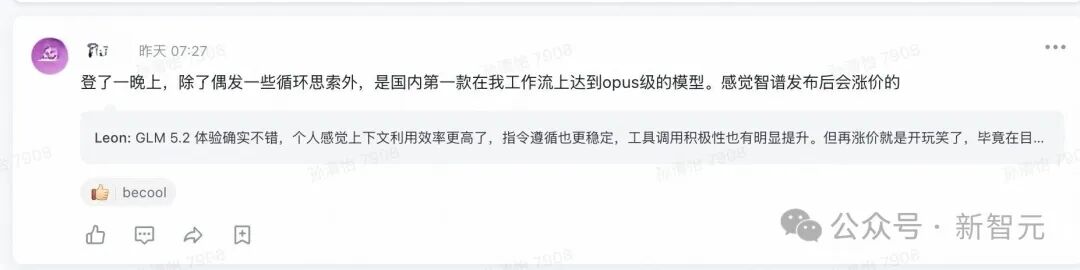
On Zhihu, someone even stated: “Starting next week, those using Opus through a proxy must face a question—if the Opus you are using is actually GLM-5.2 masquerading, you might not be able to tell, and it might even perform better.”
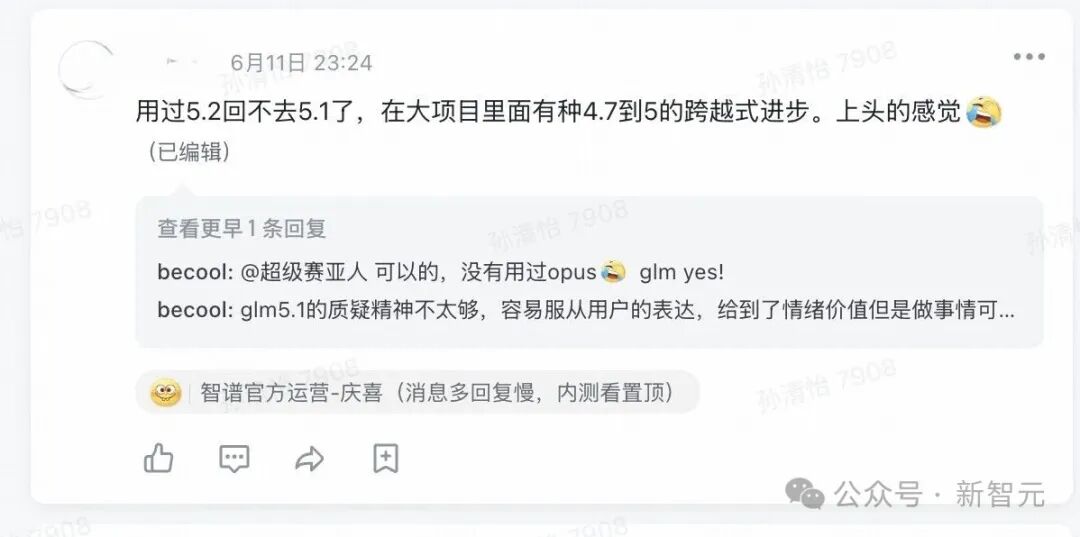
The official benchmarks are yet to be fully released, but based on the current data and feedback from developers, GLM-5.2 firmly holds the position of the top domestic coding model.
Performance Testing
After quickly obtaining internal testing qualifications, we eagerly conducted tests. Indeed, it was different from previous models.

Pathfinding Algorithms
When tasked with writing a pathfinding algorithm visualizer, GLM-5.2 delivered in one go. It successfully implemented A*, Dijkstra, and BFS algorithms without confusion.
It even wrote its own priority queue instead of using existing libraries. The most impressive part was the split-screen comparison: both algorithms ran simultaneously, each following its own path and calculations, displayed in vibrant colors—managing two independent search processes without mixing them up.
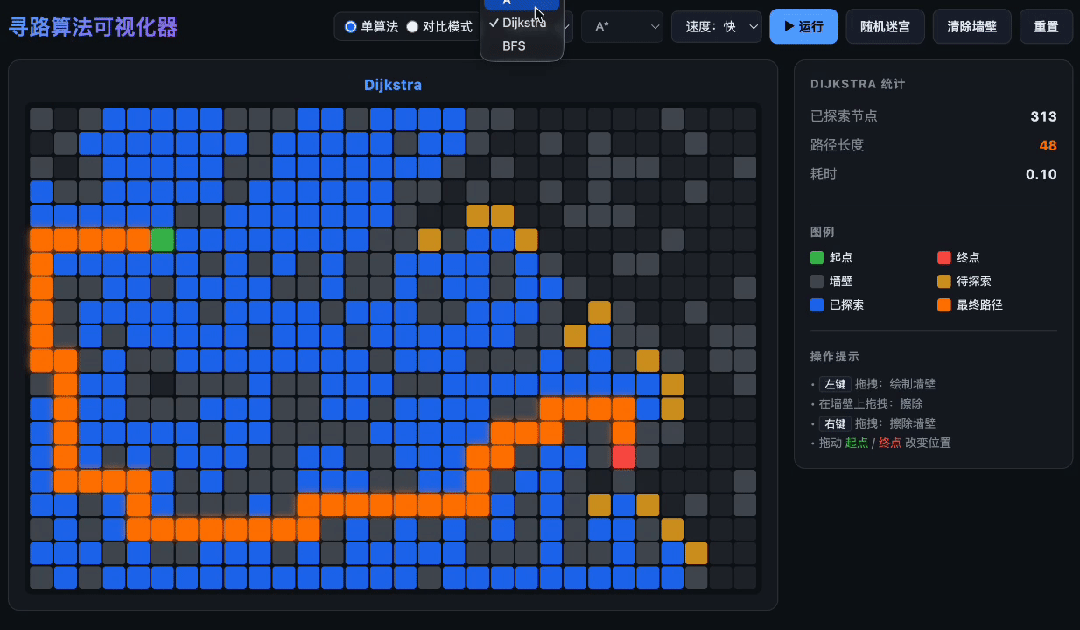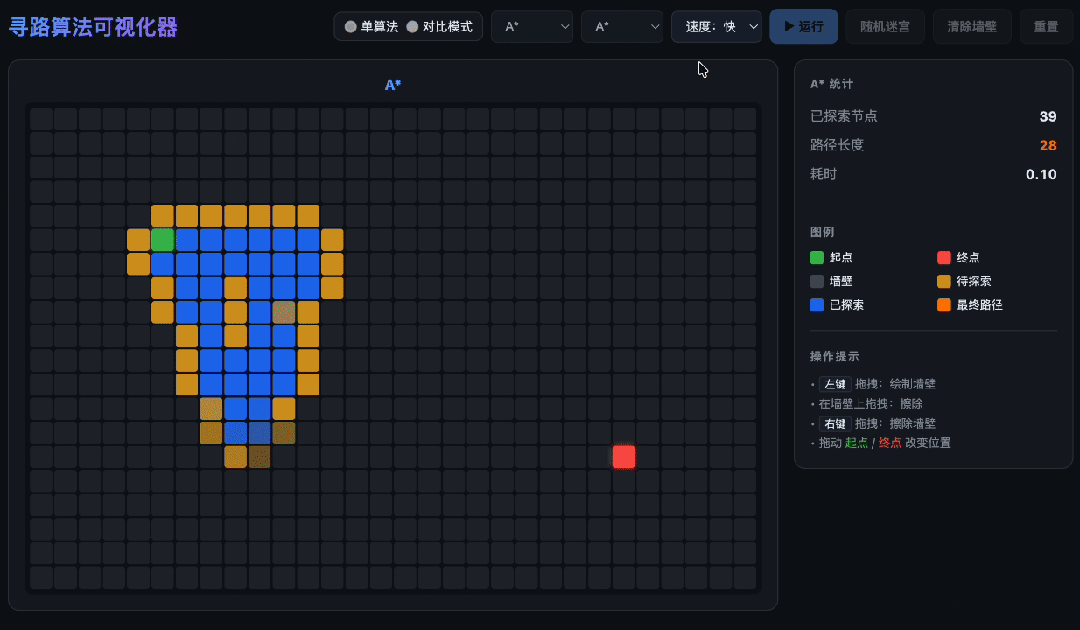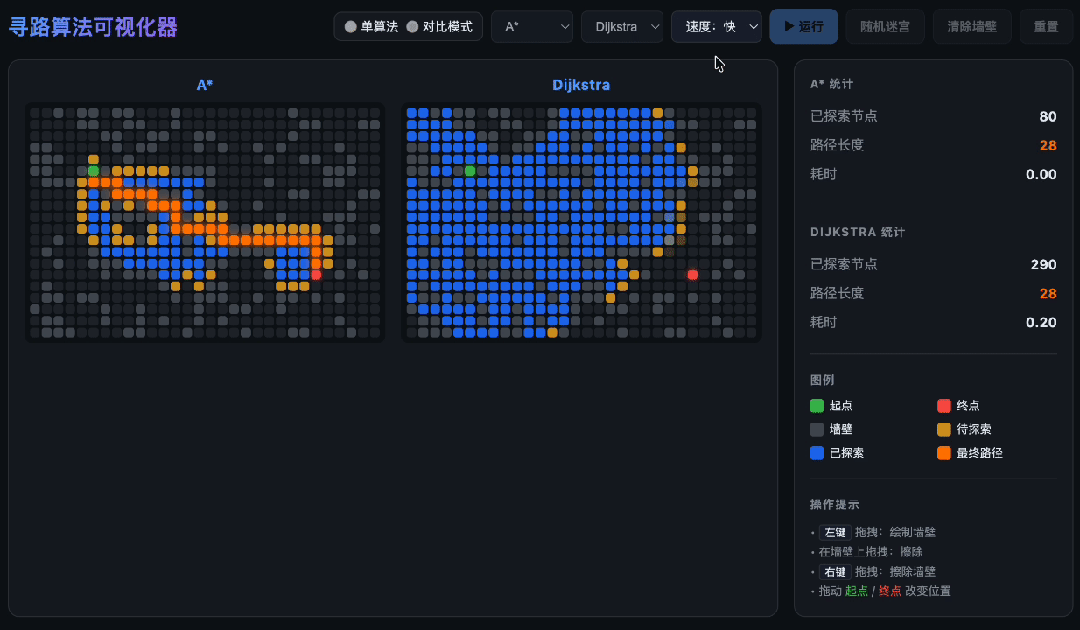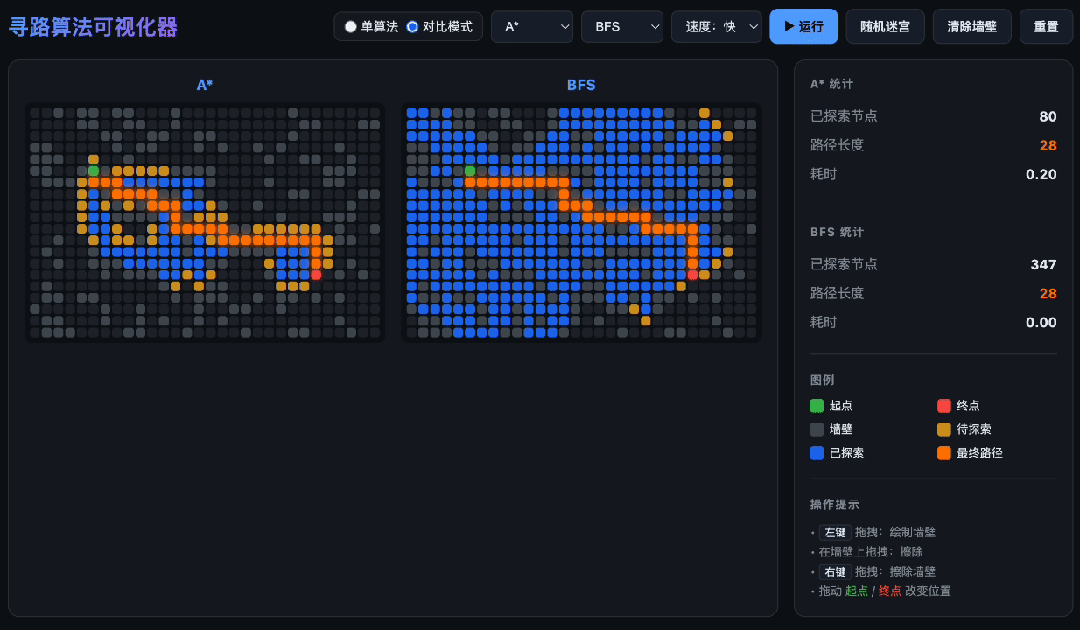
Handling Long Tasks
GLM-5.1 could autonomously work for 8 hours, but to push further, one cannot avoid a critical issue: context length.
An intelligent agent working continuously for several hours must handle thousands of tool calls, read and write tens of thousands of lines of code, and accumulate a large number of intermediate states. If the context window is not long enough, it must constantly compress and discard information. Many long tasks fail not because the model is not smart enough, but because it forgets.
Thus, the significance of 1M context is not just a larger number on a parameter table, but it allows the model to grasp an entire project in one go—remembering code, decisions, and constraints from start to finish without losing anything.
Many models claiming 1M context often struggle with retention; users have noted that while they can input data, the model does not retain it well. Many models start to “forget” after 250,000 tokens, and longer contexts demand more computational power and memory, making them slow and expensive to run.
By innovating at the structural level, Zhipu has managed to reduce both the decay of performance at 1M length and the reasoning costs.
In long text benchmarks, GLM-5.2 shows significantly less decay compared to similar models.

Real-World Application
One case that illustrates the meaning of “long tasks without forgetting” is when we tasked it with creating a professional-level HTML music synthesizer workstation using WebAudio, with zero dependencies.
It worked for four continuous hours without interruption. During this time, it wrote code, assembled 29 review agents to critique its code from four dimensions, identified and fixed 18 bugs, and ran Headless Chrome automated tests to validate the entire audio chain.
The most impressive part was that it caught a critical bug that even the reviews missed and fixed it itself.
The final output was a workload of 177,000 tokens, completed in one round.
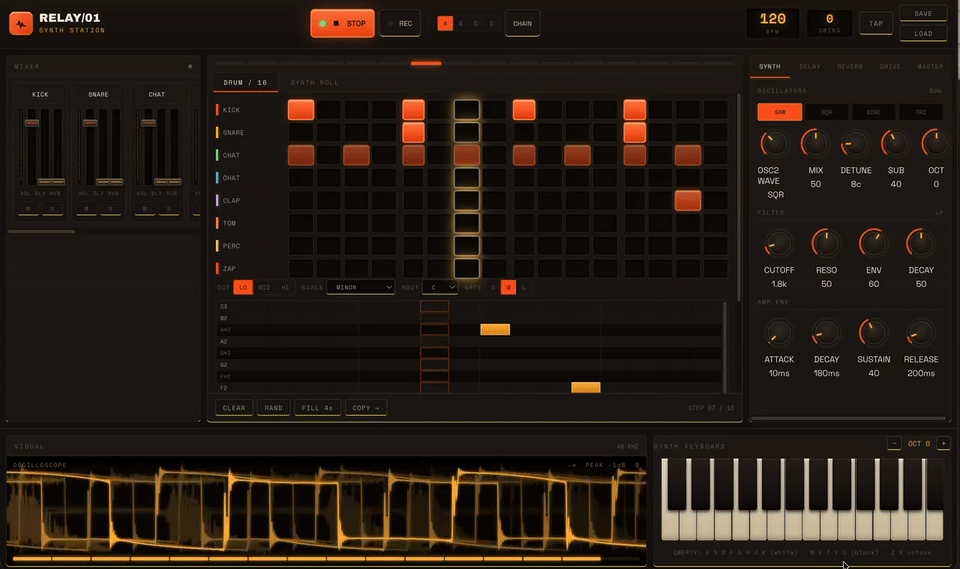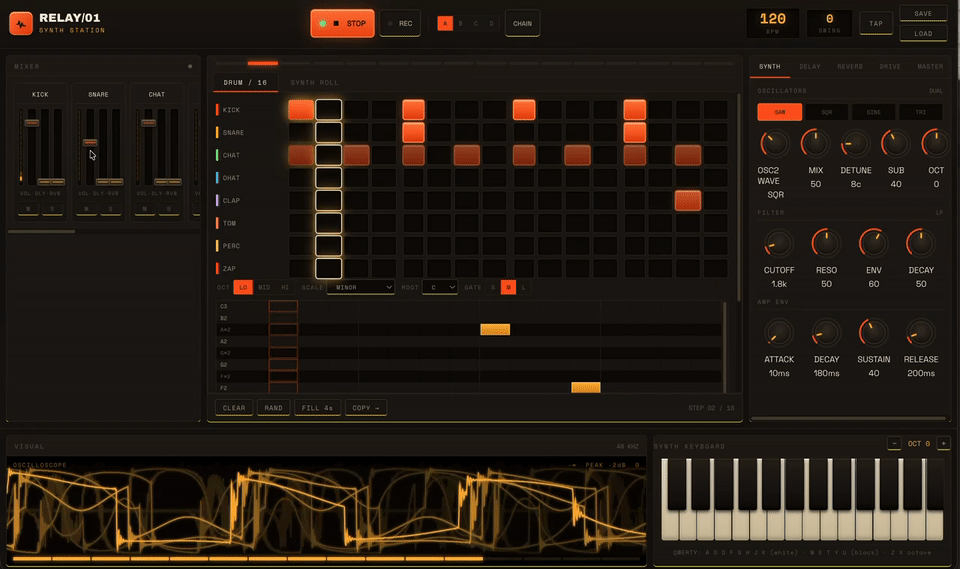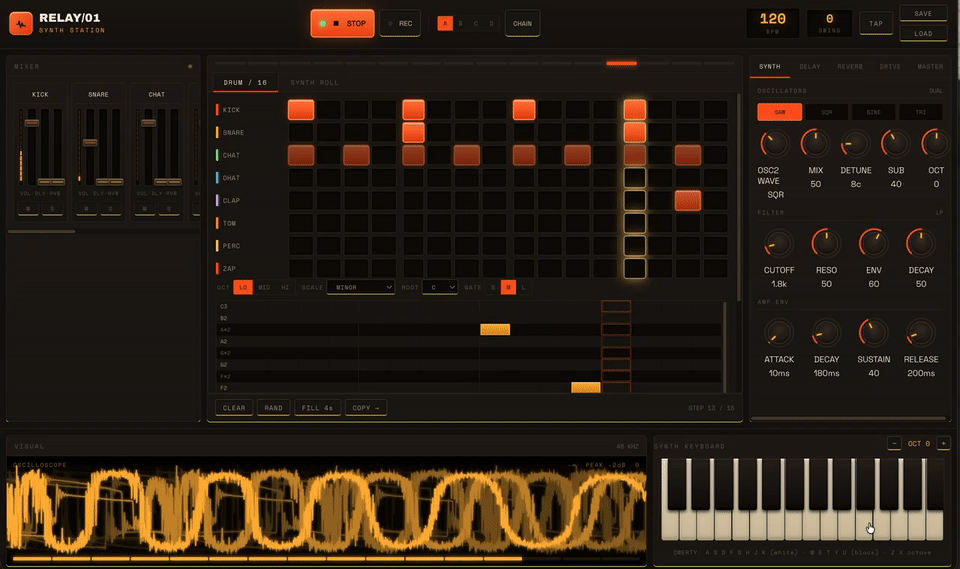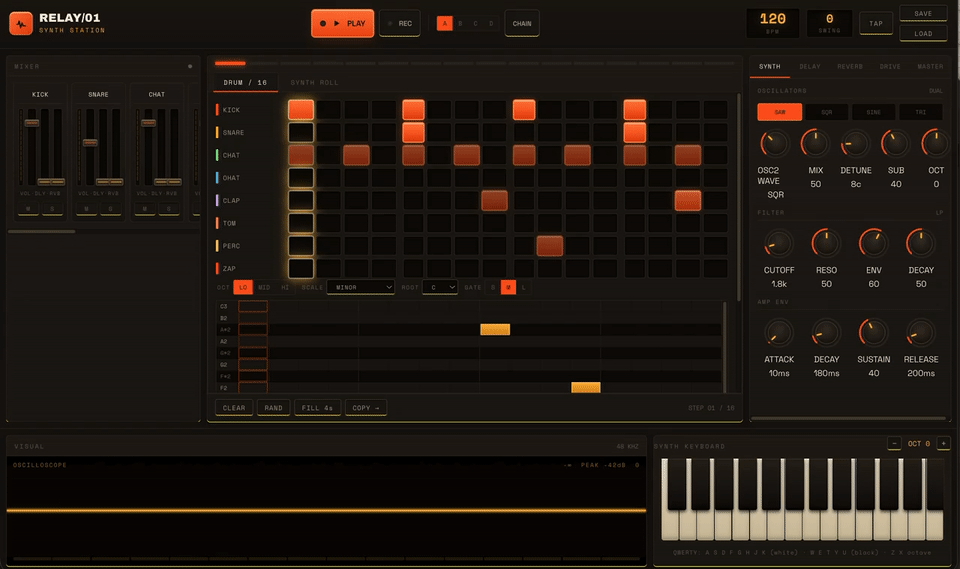
This showcases the significance of 1M context. Four hours, 170,000 tokens, and dozens of module states—all retained without loss. This is what it means to have a good memory.
Conclusion
Returning to the initial issue: Fable 5 was forcibly taken down just three days after its launch, leaving global developers without the tools they relied on. Teams that depended on Fable 5 for their products found their services abruptly halted.
You never know when the tools in your hands might be taken away by a single letter.
In the context of increasing uncertainty regarding access to closed-source frontier models overseas, the value of domestic open-source models continues to rise.
Zhipu has been committed to coding models for over a year, and this release solidifies the long-awaited 1M context and long task capabilities, making this coding model truly capable of handling complex tasks, no longer just a pretty face on the leaderboard.
Zhipu encapsulated this release in a phrase that circulated widely in the AI community: Frontier intelligence should not belong to a select few and should not be retracted at any time by a few rules. It should be open, usable, and constructible, serving every developer.

This statement resonates deeply, and we look forward to GLM’s continued progress.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.